インターネットにあるWebサイトのHTMLデータの中から、必要なデータを自動的に取得することをスクレイピングといいます。
Googleなどの検索エンジンがインデックスを作成するために、自動でWebサイトを巡回し、HTMLや画像などのデータを取得することをクローリングと言います。クローリングは、原則、リンクを手繰るだけで、HTMLの構造の解析はしません。
一方で、スクレイピングは、HTMLの構造まで解析し、所望するデータの場所を特定して、取得します。
■ スクレイピングの目的
ソフトウェアをつくる場合において、初期データを用意することは大きな課題です。たとえ、ソフトウェアが作れても、初期データがないと、運用やサービスが開始できないというジレンマに陥ります。Googleでさえ、検索エンジンを運用するには、各サイトのHTMLデータが必要です。そのためにクローリングをしています。
スクレイピングは、この初期データとして、他者が作成したデータを利用することが主な目的です。特に、商品などの検索結果の一覧を取得し、大量のデータを入手するためなどに使います。自らデータを生成する手間が省けるだけでなく、信頼度が高く良質なデータを得ることができます。
スクレイピングで収集したデータは、RDBなどによってデータベース化されたり、学習データとして定型化され機械学習に使われます。
■ スクレイピングの限界とリスク
スクレイピングは万能ではありません。以下のような限界があります。
・必要なデータを提供してくれるサイトが見つからない
自前で用意できないデータが、何でもインターネット上に落ちていると考えるのは浅はかです。逆に、見つかることの方が少数派です。
その理由は、インターネットで公開されているデータは、公開しても問題のないデータだけしか公開されていません。本当に重要なデータは、企業の機密情報として社内だけで管理されているからです。
・データを収集するまで時間がかかる
サイトへの影響がないように、データを取得する間隔をあけてアクセスする必要があります。また、1つのデータを取得するにも、インターネットを経由したアクセスとなるため少なくとも数秒かかります。必要なデータ量をすべて取り切るには数時間、数日といったように、時間がかかります。
また、スクレイピングには、インターネットという公けに公開されているデータとは言え、他者のデータを無断で入手し、利用した場合の法的なリスクがあります。
・サイトがスクレイピングを禁止している
サイトで提供しているデータは、お金と時間、そして労力をかけて収集されています。その結果、サイトの価値が上がり、他者との差別化が図られます。スクレイピングによって無料でデータを取得されると、競争力が低下する可能性があります。そのため、サイト内でも検索機能や商品一覧などの情報を提供するURL配下へのスクレイピングを許可しないサイトもあります。また、技術的に、スクレイピングからのアクセスの特徴(短時間に同じ要求元あら特定URLへのアクセスなど)を検出し、正常なレスポンスを返却しないようにしているサイトもあります。
サイトでは、クローリングによるサイトへの負荷を抑止するために、クローリングを許可あるいは禁止する場所(URL)をRobots.txtというテキストに宣言しています。
これは、スクレイピングをする際にも、原則として、遵守すべきと考えられています。これを事前に確認し、禁止されている場所(URL)へのスクレイピングは控える必要があります。
たとえば、日経新聞サイトのRobots.txtには、現時点で以下のように記載されています。
User-agent: *
Disallow: /search/site/
Disallow: /markets/kabu/stkcomp/
Disallow: /markets/kabu/gyoshucomp/
Allow: /markets/kabu/stkcomp/$
Allow: /markets/kabu/gyoshucomp/$
アクセスするブラウザに関係なく、「/markets/kabu/stkcomp/」「/markets/kabu/gyoshucomp/」より下のURLへのアクセスは許可されていますが、「/search/site/」「/markets/kabu/stkcomp/」「/markets/kabu/gyoshucomp/」以下のURLへのアクセスは禁止されています。
・収集したデータの利用に制限がある
サイトには、利用許諾があり、公開されています。この中に、スクレイピング行為そのものに対する考え方とサイト内のデータの取り扱いについて明記されています。データを提供するサイトでは、何かしらの制限事項が記載されています。
スクレイピングを実施する前に、上記のリスクをきちんと確認した上で、実施する必要があります。
たとえば、NTTグループが運営するタウンページには、免責事項・利用規約があり、禁止事項の一つに、以下のようにスクレイピングを禁止する旨が記載されています。
「自動的にアクセスするプログラムを使用してiタウンページに繰り返しアクセスする行為」
■ スクレイピングに必要な技術
スクレイピングには、以下の技術が使われます。
1)Python
変更が容易にできるスクリプト言語を使います。その中でも、スクレイピングのための環境が揃っているPythonが使われます。
Pythonの環境として、Anacondaが有名です。主に機械学習用のパッケージですが、Python単独でインストールするよりも、主要な各種ライブラリが含まれたパッケージとなっているため便利です。
2)HTTPアクセスライブラリ
Pythonから使えるHTTPプロトコルライブラリには、requestsがあります。これを使って、サイトのURLにアクセスし、HTMLを取得します。
また、Chromeブラウザ経由でHTMLを取得するためのChromeドライバーを使うseleniumライブラリもあります。Chromeブラウザ、Chromeブラウザを駆動するためのChromeDriver、そして、ChromeDriverをPythonから駆動するseleniumライブラリが必要となります。
3)HTML解析ライブラリ
Pythonには、HTMLのタグ構造に従って、細かくデータを取得できるBeatifulSoapがあります。取得したHTMLを一つ一つのタグ単位で、データを取り出すことができます。
その手順は、タグ名とclass、idなどのタグの属性を指定し、HTML内から特定のタグを個々に取得したり、一括して取得することができます。
BeatifulSoapのおかげで、スクレイピングが容易になったといってもいいでしょう。
■ スクレイピングの手順
上記の技術を使って、以下の手順でスクレイピングを実施します。
①所定のサイトへHTTPリクエストを送信し、HTMLのレスポンスを取得する。
②HTMLのレスポンスを解析し、必要なデータを取り出す。
③ ①のHTTPリクエストに指定するパラメータを変更しながら、最終のページまで①と②を繰り返す。
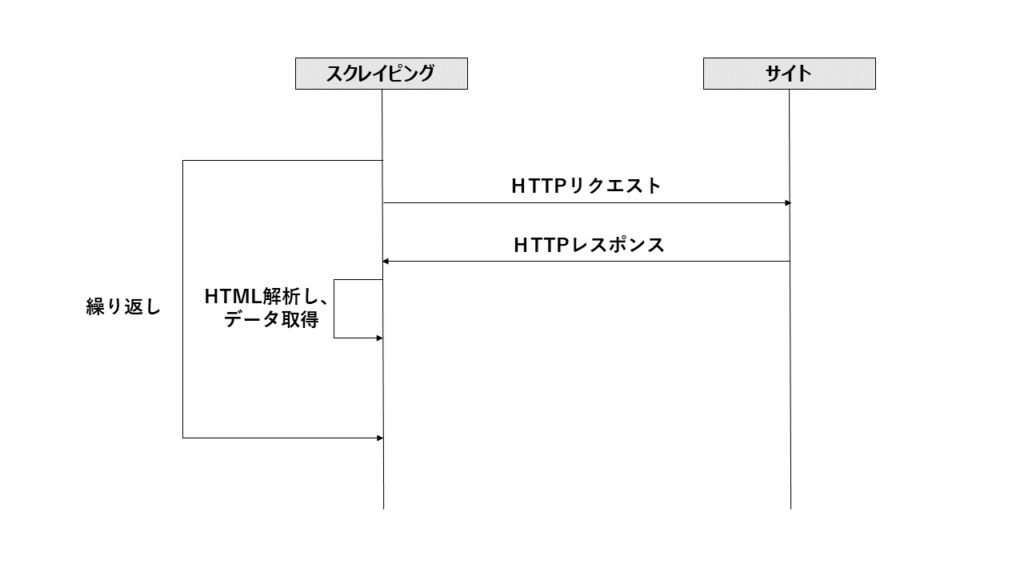
■ スクレイピングするサイトの分析
スクレイピングの手順において、以下のようにスクレイピングをするサイトの分析をします。
1)HTTPリクエストのパラメータの分析
ブラウザからスクレイピングするHTMLのページを表示させ、そのURLを確認します。
次のページを表示させた際に変化するURLの箇所やパラメータを確認し、法則性を見いだします。これにより、HTTPリクエストで変化させるURLやパラメータを確定させます。
たとえば、ブラウザで、日経TECHキャリアサイト(https://tech.nikkeihr.co.jp/)上で、「IT→システム設計・開発(WEB・オープン・モバイル系)→検索」と手繰っていくと次のようなURLとなっていることがわかります。

さらに、次のページへと進んでいくと、pg1→pg2-→pg3・・・と順番に変化するのがわかります。

このことから、URLの中の”pg”の後の番号を1づつ増加させていけば、ページを手繰っていけることがわかります。この法則性をプログラミングします。
また、ページ当たりの一覧に含まれるデータの件数が何件なのかを把握しておきます。これによって、何ページ分、HTTPリクエストを投げればいいかわかります。
2)HTMLソースの分析
スクレイピングをするコードを書くには、実際のHTMLソースの分析をして、取得したいデータがどこのタグに格納されているのかを知る必要があります。それは、取得したいデータの特徴となるタグの以下のパターンを見つけることです。
ソースは、ブラウザから表示しているページを保存するか、「ソースを表示」することで見ることができます。
・リスト形式の繰り返しパターンを見つける
一覧は、HTMLの表形式(table)、あるいは、ブロック形式(div)が列挙されるように定義されています。このパターンをソースの中から見つけます。そして、パターンを特定できるclass、idなどタグの属性を把握します。
・パターンの中の構造を把握する
パターンが特定できることがわかれば、その中のタグ構造をから取得したいデータのタグが何かを把握します。そのタグのclass、idなどタグの属性を把握します。もし、タグの属性がなければ、同じタグの中での順番を見て場所を特定していきます。tableであれば、何行名、何列目など、取得したいタグの順番を把握します。
たとえば、前述した日経TECHキャリアサイト(https://tech.nikkeihr.co.jp/)の「IT→システム設計・開発(WEB・オープン・モバイル系)→検索」と手繰ったときの画面を見ると、件数と、求人の一覧が表示されています。
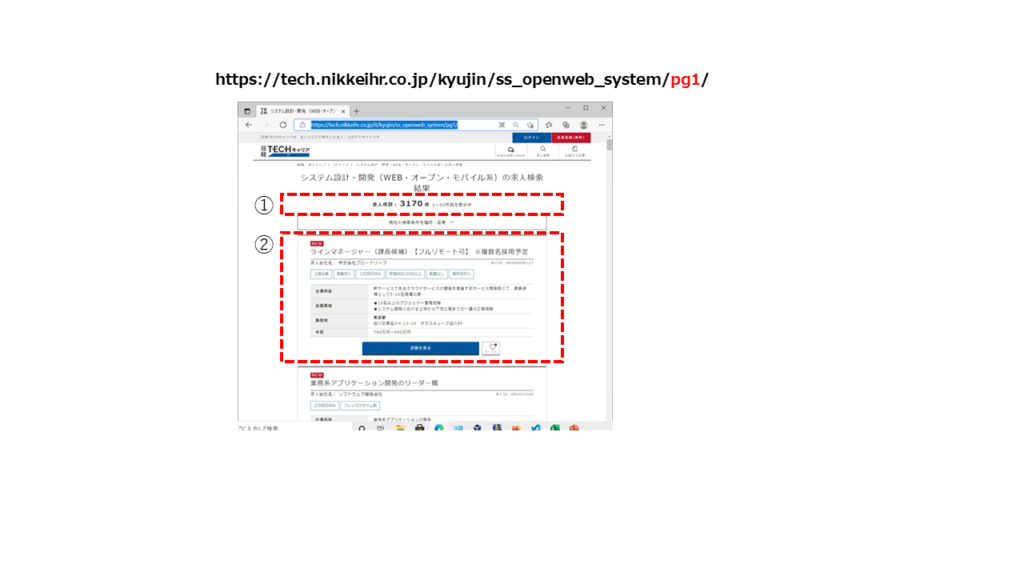
ソースを見ると、件数は「<div class=”pager-result”>~</div>」のHTMLタグに記載されています。
<div class="pager-result">
<span class="total">求人件数:<span class="num">3170</span>件</span>
<span class="now">1~50件目を表示中</span>
</div>一覧の各求人は、「 <article id=”book_mark_173139″ class=”job-list new “>~ </article>」のHTMLタグに記載されています。さらに、その中に、求人のタイトルが「 <h2 class=”title04″>~</h2>」、求人のサマリが「 <div class=”job-meta”>~</div>」のHTMLタグに記載されています。
<article id="book_mark_173139" class="job-list new ">
<!-- h2 -->
<h2 class="title04">
<a href="https://tech.nikkeihr.co.jp/it/pasonacareer/jobdetail173139/" target="_blank"><span class="main">ラインマネージャー(課長候補)【フルリモート可】 ※複数名採用予定</span></a>
</h2>
<div class="job-meta">
<p class="job-corporate">求人会社名:
株式会社ブロードリーフ </p>
<p class="job-id">求人ID:<span>NKT80828127</span></p>
</div>
<ul class="tags01">
<li style="border-color: #568591;color: #568591;">上場企業 </li>
<li style="border-color: #568591;color: #568591;"> 急募求人 </li>
<li style="border-color: #568591;color: #568591;"> 土日祝日休み </li>
<li style="border-color: #568591;color: #568591;"> 年間休日120日以上 </li>
<li style="border-color: #568591;color: #568591;"> 転勤なし </li>
<li style="border-color: #568591;color: #568591;"> 高年収求人</li>
</ul>
<div class="layout-table s-narrow">
<dl>
<dt>仕事内容</dt>
<dd>新サービスであるクラウドサービスの開発を推進するサービス開発部にて、課長候補として5-10名規模の課…</dd>
</dl>
<dl>
<dt>応募資格</dt>
<dd>■10名以上のプロジェクト管理経験<br>■システム開発における上流から下流工程までの一連の工程経験</dd>
</dl>
<dl>
<dt>勤務地</dt>
<dd>
<strong>東京都</strong>
<br>品川区東品川4-13-14 グラスキューブ品川8F </dd>
</dl>
<dl>
<dt>年収</dt>
<dd>
700万円~900万円 </dd>
</dl>
</div>
<div class="button-layout04">
<ul>
・・・・・・・省略・・・・・・・
</ul>
</div>
</article>
また、求人のタイトルのHTMLタグには、求人の詳細を表示するためのURLが含まれている箇所があり、そのURLを手繰ると求人詳細が表示されます。( <a href=”https://tech.nikkeihr.co.jp/it/pasonacareer/jobdetail173139/” target=”_blank”>)
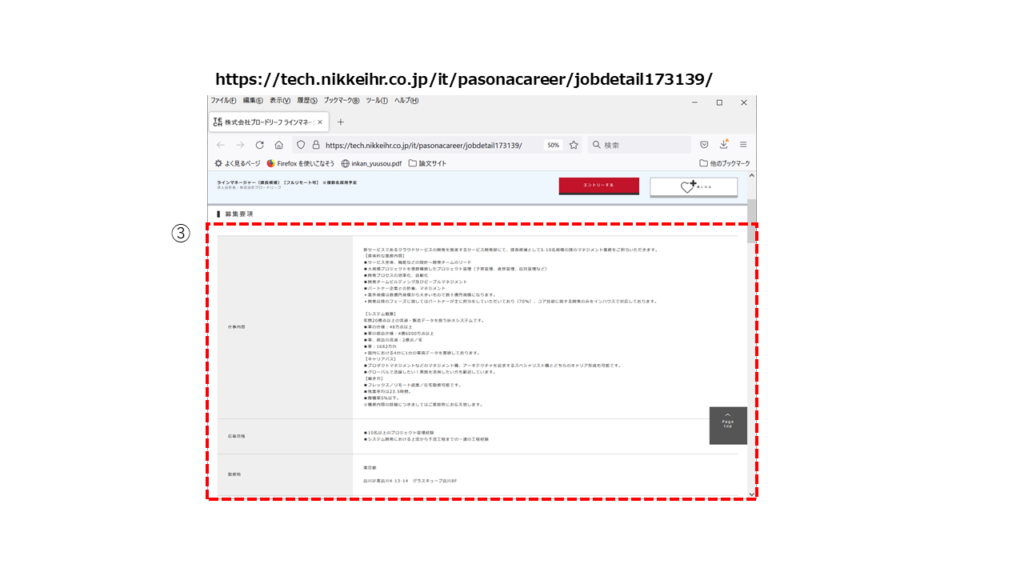
ソースを見ると、求人の詳細が「<div class=”layout-table “>~</div>」のHTMLタグに記載されています。その中で、仕事内容、応募資格、勤務地などが個々のデータが「 <dl>~</dl>」のHTMLタグに記載されています。
<div class="layout-table ">
<dl>
<dt>仕事内容</dt>
<dd>新サービスであるクラウドサービスの開発を推進するサービス開発部にて、課長候補として5-10名規模の課のマネジメント業務をご担当いただきます。<br>【具体的な業務内容】<br>■サービス全体、機能などの設計~開発チームのリード<br>■大規模プロジェクトを複数横断したプロジェクト管理(予算管理、進捗管理、品質管理など)<br>■開発プロセスの効率化、自動化<br>■開発チームビルディング及びピープルマネジメント<br>■パートナー企業との折衝、マネジメント<br>*案件規模は数億円規模から大きいもので数十億円規模になります。<br>*開発以降のフェーズに関してはパートナーが主に担当をしていただいており(70%)、コア技術に関する開発のみをインハウスで対応しております。<br><br>【システム概要】<br>年間20億点以上の流通・製造データを扱う巨大システムです。<br>■車の仕様:48万点以上<br>■車の部品仕様:4億6000万点以上<br>■車、部品の流通:2億点/年<br>■車:1682万台<br>*国内における4台に1台の車両データを蓄積しております。<br>【キャリアパス】<br>■プロダクトマネジメントなどのマネジメント職、アーキテクチャを追求するスペシャリスト職とどちらのキャリア形成も可能です。<br>■グローバルで活躍したい!英語を活用したい方も歓迎しています。 <br>【働き方】<br>■フレックス/リモート就業/在宅勤務可能です。<br>■残業平均は23.5時間。<br>■離職率5%以下。<br>※職務内容の詳細につきましてはご面談時にお伝え致します。</dd>
</dl>
<dl>
<dt>応募資格</dt>
<dd>■10名以上のプロジェクト管理経験<br>■システム開発における上流から下流工程までの一連の工程経験</dd>
</dl>
<dl>
<dt>勤務地</dt>
<dd>
東京都
<br><br>
品川区東品川4-13-14 グラスキューブ品川8F </dd>
</dl>
<dl>
<dt>勤務時間</dt>
<dd>09:00~17:30</dd>
</dl>
<dl>
<dt>年収</dt>
<dd>
700万円~900万円</dd>
</dl>
<dl>
<dt>待遇</dt>
<dd>通勤手当、地域手当、退職金制度<br>役職手当、扶養手当、社員持株会、資格取得支援制度、保養所・スポーツ施設等、長期休業所得補償制度、結婚・出産・入学祝金、特別見舞金、フラワーメッセージ等</dd>
</dl>
・・・・・・・省略・・・・・・・
</div>
■ スクレイピングの実例
前述した日経TECHキャリアサイト(https://tech.nikkeihr.co.jp/)の「IT→システム設計・開発(WEB・オープン・モバイル系)→検索」と手繰って求人一覧から求人データを実際にスクレイピングしてみます。
以下のような処理フローとなります。
①HTTPリスエストを送信し、HTTPレスポンスからHTMLを取得する
(短すぎる間隔でのアクセスはサイトへの負荷をかけるだけではなく、不正アクセスとみなされる可能性があります。そのため一定時間を空けてアクセスします。また、通信状況によってはつながらない場合もあるリトライします)
②BeautifulSoupでHTMLの要素を抽出する
③最初のページから全件数を取得し、ページあたりに含まれる件数から何ページ分取得すればいいかを算出する
④ページ内の全タイトル部分のHTMLを取得
⑤求人詳細URLを取得
⑥求人詳細URLにアクセスし、求人のデータを取得する
⑦取得したデータを保存する
⑧ページ内の全タイトル分だけ⑤~⑦を繰り返す
⑨全ページ分、①~⑧を繰り返す
# -*- coding: utf-8 -*-
import sys
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
#
# HTTPリクエスト・レスポンスの送受信関数
#
def ConnectUrl(target_url):
data = ''
ConnectRetryCount = 0
while True: # 無限ループ
try:
# HTTPリクエスト送信
r = requests.get(target_url)
# 受信したHTTPレスポンスからHTMLを取得
data = r.text
break
except:
print('*****接続失敗*****\n'+str(target_url)+'\n')
#接続失敗した場合、リトライを3回実施する
if ConnectRetryCount < 3:
print('Wait 15Sec\n')
#15秒待ってリトライ
time.sleep(15)
ConnectRetryCount += 1
continue
else:
break
return data
#
# 求人詳細取得関数
#
def GetDetail(target_url):
# 15秒待つ
time.sleep(15)
data = ConnectUrl(target_url)
# BeautifulSoupでHTMLの要素を抽出
soup = BeautifulSoup(data, 'lxml')
# HTMLの要素からすべての「<div class="layout-table ">~</div>」のHTMLタグを取得
details = soup.find_all("div", attrs={"class": "layout-table"})
company = ''
work = ''
license = ''
place = ''
salary = ''
# すべての「<div class="layout-table ">~</div>」のHTMLタグの繰り返しループ
for detail in details:
# 個々の「<div class="layout-table ">~</div>」のHTMLタグからdtタグ,ddタグを全て取り出す
dts = detail.find_all("dt")
dds = detail.find_all("dd")
# 個々のdtタグ,ddタグから必要なデータを取り出す
for index, dt in enumerate(dts):
dt_value = dt.text.strip()
dd_value = dds[index].text.strip()
if dt_value == '仕事内容':
work = dd_value
continue
if dt_value == '応募資格':
license = dd_value
continue
if dt_value == '勤務地':
place = dd_value
continue
if dt_value == '年収':
salary = dd_value
continue
if dt_value == '求人会社名':
company = dd_value
continue
return company,work,license,place,salary
#
# メイン処理
#
if __name__ == "__main__":
# 引数の取得(CSVを出力するファイル名を指定する)
args = sys.argv
if len(args) < 2:
print('USAGE: GetDataNikkeiTech.py <outputfile>')
exit
#CSVを出力するファイル名
param_outputfile = args[1]
# proxy_servers経由の場合、プロキシの指定をする必要がある
'''
proxies = {
"http":"http://proxy.XXX.co.jp:8080",
"https":"http://proxy.XXX.co.jp:8080"
}
'''
# PandasのDataFrameを作成する
df = pd.DataFrame([],columns=['company','work','license','place','salary'])
#ページ番号の開始を設定
PageNo = 1
#ページに含まれる件数を設定(50件)
KENSU_PER_PAGE =50
# データ取得の繰り返し
TotalPage = 0
while True:
# URLを指定(ページ番号を指定)
target_url = 'https://tech.nikkeihr.co.jp/it/kyujin/ss_openweb_system/pg'+str(PageNo)+'/'
# HTTPリクエスト・レスポンスの送受信
data = ConnectUrl(target_url)
if len(data) == 0:
break
# BeautifulSoupでHTMLの要素を抽出
soup = BeautifulSoup(data, 'lxml')
if PageNo == 1:
# 最初のページの場合
# HTMLの要素から「<div class="pager-result ">~</div>」のHTMLタグを取得
kensu_data = soup.find("div", attrs={"class": "pager-result"})
# さらに「<span class="total">~</span>」のHTMLタグを取得
kensu_data = kensu_data.find("span",attrs={"class": "total"})
# さらに「<span class="num">~</span>」のHTMLタグを取得
kensu_data = kensu_data.find("span",attrs={"class": "num"})
# テキストから件数を取得
kensu = kensu_data.text.strip()
kensu = int(kensu)
print(kensu)
# ページあたりに含まれる件数から何ページ分取得すればいいかを算出する
if (kensu % KENSU_PER_PAGE) ==0 :
TotalPage = int((kensu / KENSU_PER_PAGE ))
else:
TotalPage = int((kensu / KENSU_PER_PAGE )) + 1
# 全タイトル部分のHTMLを取得
title_data_all = soup.find_all("h2", attrs={"class": "title04"})
# ページ内の全タイトル分の繰り返しループ
for title_url in title_data_all:
try:
# 求人詳細URLを取得
title_url = title_url.find("a")
title_url = title_url['href']
detail_url = 'https://tech.nikkeihr.co.jp'+title_url
company,work,license,place,salary = GetDetail(detail_url)
# 仕事内容、会社名があるか判断
if work != '' and company != '' :
#取得したデータ行を生成し、DataFrameに追加
row = pd.Series([company,work,license,place,salary], index=df.columns)
df = df.append(row,ignore_index=True)
except:
print('*****例外発生*****\n'+'継続\n')
continue
print('取得='+str(len(df))+' '+'ページ数='+str(PageNo)+'/'+str(TotalPage))
#カウントアップ
PageNo += 1
#全ページ取得したらブレーク
if PageNo > TotalPage :
break
# 15秒待って継続する
time.sleep(15)
#全ページ取得したら、CSV形式で保存
if PageNo > TotalPage :
df.to_csv(param_outputfile)
else:
#途中で中断した場合も、途中まででCSV保存
df.to_csv(param_outputfile+'_STOP_AT_PAGENO_'+str(PageNo))■ スクレイピングの失敗を抑止する方法
サイトには、ブラウザとセッションを管理するものもあり、セッションがないとアクセスできないようにしているサイトもあります。セッションはCookieのデータとして設定されますが、HTTPSの場合、暗号化されていて単にHTTPリクエストを送信するだでは、スクレイピングできない場合もあります。
また、次ページを表示する際、URLやパラメータにページ番号を指定するような方法ではなく、「もっと見る」ボタンの押下によって次ページを表示させるサイトもあります。
そのような場合、seleniumライブラリを使い、ブラウザ(Chrome)経由でサイトにアクセスする必要があります。(実践入門「スクレイピング」とは?(その2)に続く)
ソフトウェア開発・システム開発業務/セキュリティ関連業務/ネットワーク関連業務/最新技術に関する業務など、「学習力×発想力×達成力×熱意」で技術開発の実現をサポート。お気軽にお問合せ下さい









