次に、seleniumライブラリを使ったスクレイピングについて、解説します。
サイトには、ブラウザとセッションを管理するものもあり、セッションがないとアクセスできないようにしているサイトもあります。セッションはCookieのデータとして設定されますが、HTTPSの場合、暗号化されていて単にHTTPリクエストを送信するだでは、スクレイピングできない場合もあります。
また、次ページを表示する際、URLやパラメータにページ番号を指定するような方法ではなく、「もっと見る」ボタンの押下によって次ページを表示させるサイトもあります。
このような場合、 seleniumライブラリ を使ってサイトにアクセスし、スクレイピングを実施します。
■ seleniumライブラリとは
Seleniumとは各プログラム言語(Java/Python/C#/Ruby/JavaScript/Kotlin)からブラウザ(Chrome/FireFox/IE/Edge/Safari/Opera)を操作するためのライブラリなどの環境を提供するプロジェクトです。WebDriverと呼ばれる各ブラウザに対応した実行ファイルを経由して、各プログラム言語からブラウザを操作します。
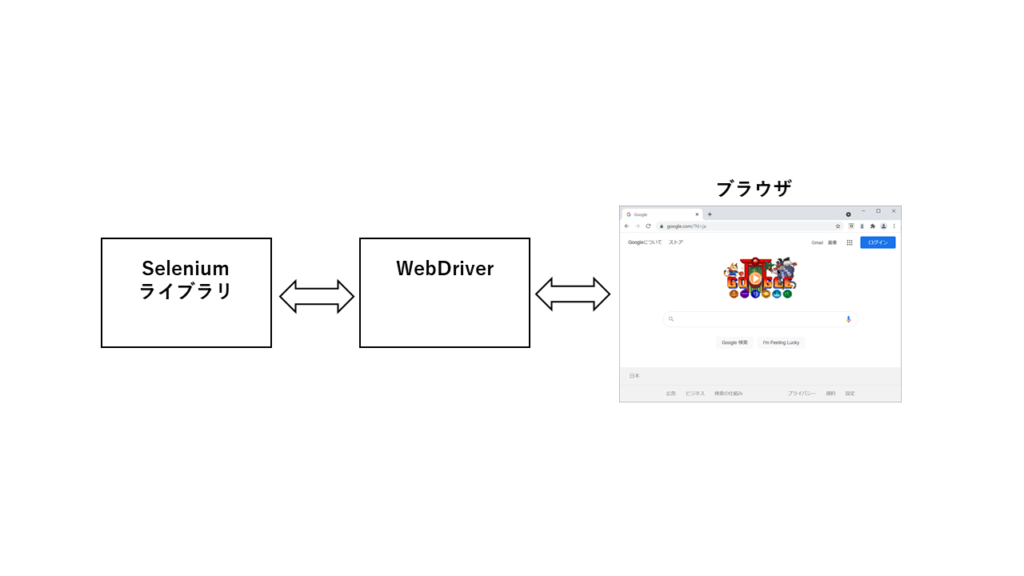
Python+Chromeの場合、以下の環境が必要です。
1)Python
変更が容易にできるスクリプト言語を使います。その中でも、スクレイピングのための環境が揃っているPythonが使われます。
Pythonの環境として、Anacondaが有名です。主に機械学習用のパッケージですが、Python単独でインストールするよりも、主要な各種ライブラリが含まれたパッケージとなっているため便利です。
2)PythonのSeleniumライブラリ
以下を実行することでインストールできます。
pip install selenium
2)Chromeブラウザ
ここからダウンロードし、インストールします。
3)ChromeのWebDriver
ここからダウンロードし、実行ファイルを取得します。
注意点は、ChromeのバージョンにあったWebDriverを選んでダウンロードすることです。
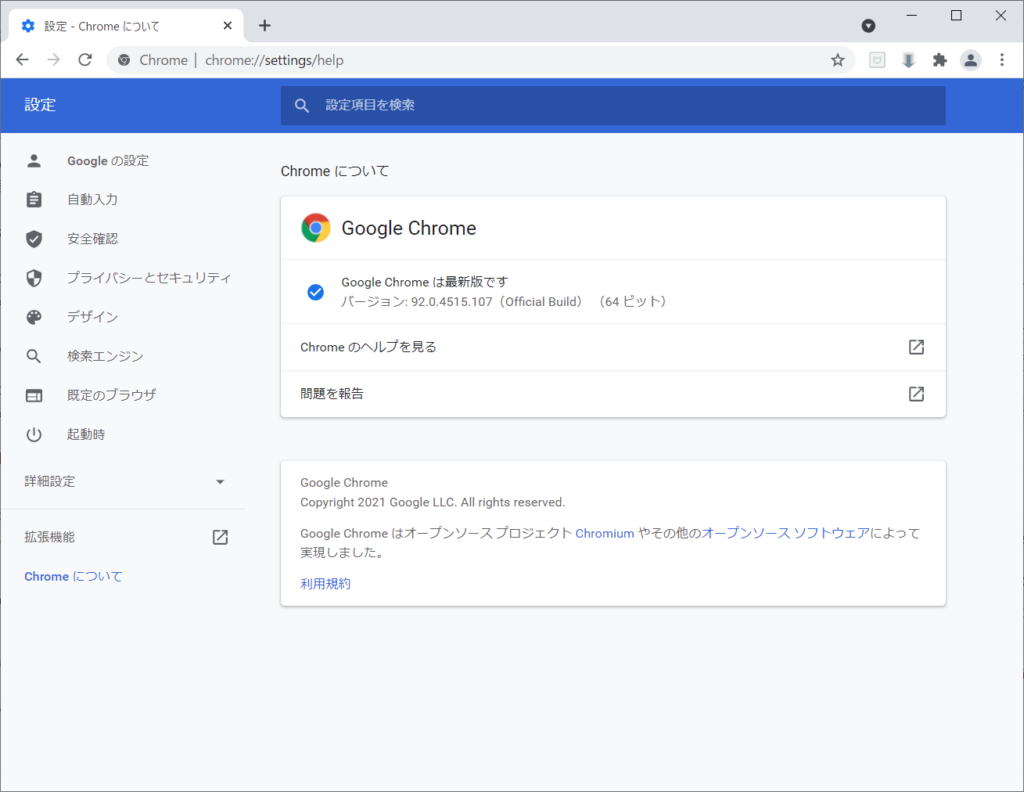
Chromeのバージョン は、Chromeを立ち上げ、「ヘルプ→Google Chromeについて」を参照することで確認できます。本ブログの例では、ver92の「ChromeDriver 92.0.4515.43」を利用しています。
■ seleniumライブラリ を使ったスクレイピングの実例
弱者のための「スクレイピング」入門(1/2)の「■スクレイピングの実例」と原則、同じ流れです。です
異なるのはHTTPリクエスト・レスポンスの送受信関数をWebDriver対応に置き換えている点です。
これによって、HTTPプロトコルを直接駆動するのではなく、Chrome経由でHTTPプロトコルを駆動し、データを取得します。
# -*- coding: utf-8 -*-
import sys
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# Seleniumライブラリのインポート
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
#
# WebDriverの初期化関数
#
def InitWebDrv():
options = Options()
# オプションに画面を表示せずに動作するモードを指定
options.add_argument('--headless')
# オプションにGoogleから暫定的に必要といわれているフラグを指定
options.add_argument('--disable-gpu')
#Chromeの実行ファイルのパスを設定
options.binary_location = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe"
#WebDriverの実行ファイルのパスを指定し、WebDriverのインスタンスを生成
driver = webdriver.Chrome(chrome_options=options, executable_path="C:\\Users\\swata\\Desktop\\Python\\Python\\it\\chromedriver_win32\\chromedriver.exe")
return driver
#
# WebDriverの終了関数
#
def EndWebDrv(driver):
driver.close()
driver.quit()
#
# HTTPリクエスト・レスポンスの送受信関数(WebDriver対応)
#
def ConnectUrl_WebDrv(target_url):
# WebDriver経由でChromeがサイトにアクセスする際、各ブラウザ毎・OS毎のUserAgentに設定する値のリスト
df_ua = pd.DataFrame([
['Chrome Win7','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1'],
['Chrome Win10','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'],
['Firefox Win7','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'],
['Firefox Win10','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0'],
['IE9','Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR'],
['IE11','Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; rv:11.0) like Gecko'],
],
columns=['name','ua'])
data = ''
ConnectRetryCount = 0
while True: # 無限ループ
try:
# HTTPリクエスト送信
driver.get(target_url)
# 受信したHTTPレスポンスからHTMLを取得
data = driver.page_source
break
except:
print('*****接続失敗*****\n'+str(target_url)+'\n')
#接続失敗した場合、リトライを3回実施する
if ConnectRetryCount < 3:
print('Wait 15Sec\n')
#15秒待ってリトライ
time.sleep(15)
ConnectRetryCount += 1
continue
else:
break
return data
#
# 求人詳細取得関数
#
def GetDetail(target_url):
# 15秒待つ
time.sleep(15)
data = ConnectUrl_WebDrv(target_url)
# BeautifulSoupでHTMLの要素を抽出
soup = BeautifulSoup(data, 'lxml')
# HTMLの要素からすべての「<div class="layout-table ">~</div>」のHTMLタグを取得
details = soup.find_all("div", attrs={"class": "layout-table"})
company = ''
work = ''
license = ''
place = ''
salary = ''
# すべての「<div class="layout-table ">~</div>」のHTMLタグの繰り返しループ
for detail in details:
# 個々の「<div class="layout-table ">~</div>」のHTMLタグからdtタグ,ddタグを全て取り出す
dts = detail.find_all("dt")
dds = detail.find_all("dd")
# 個々のdtタグ,ddタグから必要なデータを取り出す
for index, dt in enumerate(dts):
dt_value = dt.text.strip()
dd_value = dds[index].text.strip()
if dt_value == '仕事内容':
work = dd_value
continue
if dt_value == '応募資格':
license = dd_value
continue
if dt_value == '勤務地':
place = dd_value
continue
if dt_value == '年収':
salary = dd_value
continue
if dt_value == '求人会社名':
company = dd_value
continue
return company,work,license,place,salary
#
# メイン処理
#
if __name__ == "__main__":
# 引数の取得(CSVを出力するファイル名を指定する)
args = sys.argv
if len(args) < 2:
print('USAGE: GetDataNikkeiTech.py <outputfile>')
exit
#CSVを出力するファイル名
param_outputfile = args[1]
# proxy_servers経由の場合、プロキシの指定をする必要がある
'''
proxies = {
"http":"http://proxy.XXX.co.jp:8080",
"https":"http://proxy.XXX.co.jp:8080"
}
'''
# WebDriverの初期化
driver=InitWebDrv()
# PandasのDataFrameを作成する
df = pd.DataFrame([],columns=['company','work','license','place','salary'])
#ページ番号の開始を設定
PageNo = 1
#ページに含まれる件数を設定(50件)
KENSU_PER_PAGE =50
# データ取得の繰り返し
TotalPage = 0
while True:
# URLを指定(ページ番号を指定)
target_url = 'https://tech.nikkeihr.co.jp/it/kyujin/ss_openweb_system/pg'+str(PageNo)+'/'
# HTTPリクエスト・レスポンスの送受信
data = ConnectUrl_WebDrv(target_url)
if len(data) == 0:
break
# BeautifulSoupでHTMLの要素を抽出
soup = BeautifulSoup(data, 'lxml')
if PageNo == 1:
# 最初のページの場合
# HTMLの要素から「<div class="pager-result ">~</div>」のHTMLタグを取得
kensu_data = soup.find("div", attrs={"class": "pager-result"})
# さらに「<span class="total">~</span>」のHTMLタグを取得
kensu_data = kensu_data.find("span",attrs={"class": "total"})
# さらに「<span class="num">~</span>」のHTMLタグを取得
kensu_data = kensu_data.find("span",attrs={"class": "num"})
# テキストから件数を取得
kensu = kensu_data.text.strip()
kensu = int(kensu)
print(kensu)
# ページあたりに含まれる件数から何ページ分取得すればいいかを算出する
if (kensu % KENSU_PER_PAGE) ==0 :
TotalPage = int((kensu / KENSU_PER_PAGE ))
else:
TotalPage = int((kensu / KENSU_PER_PAGE )) + 1
# 全タイトル部分のHTMLを取得
title_data_all = soup.find_all("h2", attrs={"class": "title04"})
# ページ内の全タイトル分の繰り返しループ
for title_url in title_data_all:
try:
# 求人詳細URLを取得
title_url = title_url.find("a")
title_url = title_url['href']
detail_url = 'https://tech.nikkeihr.co.jp'+title_url
company,work,license,place,salary = GetDetail(detail_url)
# 仕事内容、会社名があるか判断
if work != '' and company != '' :
#取得したデータ行を生成し、DataFrameに追加
row = pd.Series([company,work,license,place,salary], index=df.columns)
df = df.append(row,ignore_index=True)
except:
print('*****例外発生*****\n'+'継続\n')
continue
print('取得='+str(len(df))+' '+'ページ数='+str(PageNo)+'/'+str(TotalPage))
#カウントアップ
PageNo += 1
#全ページ取得したらブレーク
if PageNo > TotalPage :
break
# 15秒待って継続する
time.sleep(15)
#全ページ取得したら、CSV形式で保存
if PageNo > TotalPage :
df.to_csv(param_outputfile)
else:
#途中で中断した場合も、途中まででCSV保存
df.to_csv(param_outputfile+'_STOP_AT_PAGENO_'+str(PageNo))
# WebDriverの終了
EndWebDrv(driver)
■ WebDriverから「もっと見る」ボタンをクリックする
Chrome経由でHTTPプロトコルを駆動し、データを取得することのメリットは、ブラウザで取得したHTMLを表示して、画面操作をすることができることです。
例えば、URLの引数でページ番号を指定して次ページが表示する方法でなく、「もっと見る」ボタン によって表示するサイトの場合でも、以下のようにWebDriver経由で 「もっと見る」ボタン をクリックすることで次ページを表示できます。
# HTTPリクエスト送信
driver.get(target_url)
try:
# 「もっと見る」ボタンをクラス名で探索
while driver.find_element_by_class_name("m-read-more"):
# 「もっと見る」ボタンのインスタンスを取得
elem = driver.find_element_by_class_name('m-read-more')
# 「もっと見る」ボタンをクリック
elem.click()
# HTMLデータが取得されるまで待つ
time.sleep(5)
# HTMLデータを取得されるまで待つ
data = driver.page_source
# Whileループの探索で「もっと見る」ボタンが見つからない場合=最終ページと判断し、例外をスルー
except NoSuchElementException:
pass
■ まとめ
スクレイピングは、データを入手するには便利ですが、あくまでも他者の作ったデータを収集していることを念頭に実施することが重要です。取得しても問題ないデータなのかを確認し、また、収集したデータは原則そのまま公開はできないことを理解した上で行う必要があります。
大量のデータを取集するには、ある程度の期間がスクレイピングを実施する必要があります。
そのため、無駄な時間にならないように、何を目的としたデータ収集なのかを明確にしてから実施するべきです。
闇雲にスクレイピングしても、ただゴミを集めただけという結果とならないようにするために。
ソフトウェア開発・システム開発業務/セキュリティ関連業務/ネットワーク関連業務/最新技術に関する業務など、「学習力×発想力×達成力×熱意」で技術開発の実現をサポート。お気軽にお問合せ下さい









